For all the technology we have, it can still be frustratingly difficult to get any concrete information from the media. Sometimes all you want to do is to cut through the noise and see some real numbers. Watching talking heads argue for a half hour probably isn’t going to tell you much about how the COVID-19 virus is spreading through your local community, but seeing real-time data pulled from multiple vetted sources might.
Having access to the raw data about COVID-19 cases, fatalities, and recoveries is, to put it mildly, eye-opening. Even if day to day life seems pretty much unchanged in your corner of the world, seeing the rate at which these numbers are climbing really puts the fight into perspective. You might be less inclined to go out for a leisurely stroll if you knew how many new cases had popped up in your neck of the woods during the last 24 hours.
But this article isn’t about telling you how to feel about the data, it’s about how you can get your hands on it. What you do with it after that is entirely up to you. Depending on where you live, the numbers you see might even make you feel a bit better. It’s information on your own terms, and in these uncertain times, that might be the best we can hope for.
Scraping the CDC Website
If you’re in the United States, then the Centers for Disease Control and Prevention is perhaps the single most reliable source of COVID-19 data right now. Unfortunately, while the agency offers a wealth of data through their Open Data APIs, it seems that things are moving a bit too fast for them to catch up at the moment. At the time of this writing there doesn’t appear to be an official API to pull from, only a human-readable website.

Of course if we can read it, than so can the computer. The website is simple enough that we can split out the number of total cases with nothing more than a few lines of Python, we don’t even need to use a formal web scraping library. It should be noted that this isn’t a good idea under normal circumstances as changes to the site layout could break it, but this (hopefully) isn’t something we need to be maintaining for very long.
import requests
# Download webpage
response = requests.get('https://www.cdc.gov/coronavirus/2019-ncov/cases-updates/cases-in-us.html')
# Step through each line of HTML
for line in response.text.splitlines():
# Search for cases line
if "Total cases:" in line:
# Split out just the number
print(line.split()[2][:-5])
Everything should be pretty easy to understand in that example except perhaps the last line. Basically it’s taking the string from the web page, splitting it up using spaces as delimiters, and then cutting the last five characters off the back to remove the closing HTML tag. Definitely a hack, but that’s sort of what this site is all about.
There are a couple important things you need to remember when pulling data from the CDC like this. First of all, since the website is an important source of information right now, don’t hammer it. There’s really no reason to hit the page more than once or twice a day. Second, even in a pandemic the CDC is apparently keeping normal business hours; the website says the stats will only be updated Monday through Friday.
Johns Hopkins Unofficial API
A better option, especially if you’re looking for global data, is using the database maintained by the Johns Hopkins University Center for Systems Science and Engineering (JHU CSSE). This data is collected from multiple sources all over the globe and is being updated constantly. Whether or not you realized it at the time, there’s an excellent chance you’ve already seen their online dashboard as it’s become an invaluable reference to anyone tracking the progress of COVID-19.
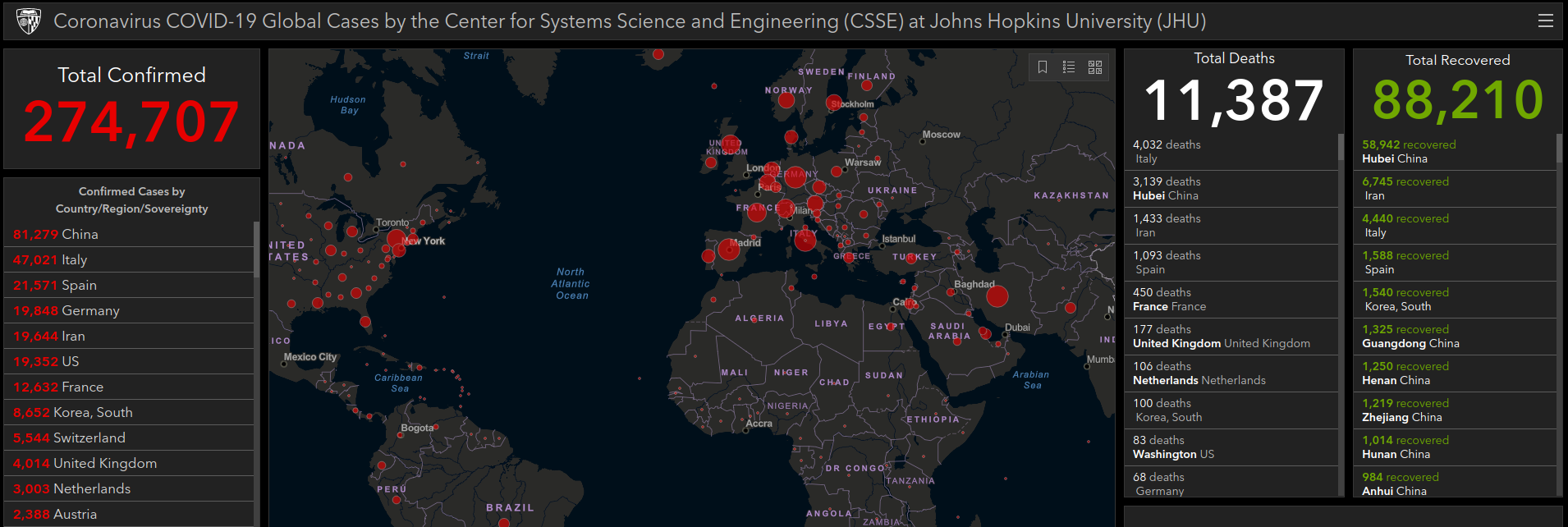
This data is published to an official GitHub repository on a daily basis for anyone who wants to clone it locally, but that’s not terribly convenient for our purposes. Luckily, French data scientist Omar Laraqui has put together a web API that we can use to easily poll the database without having to download the entire thing.
His API offers a lot of granularity, and allows you to do things like see how many cases or recoveries there are in specific provinces or states. You need to experiment around with the location codes a bit since there doesn’t appear to be a listing available, but once you’ve found the ID for where you want to look it’s easy to pull the latest stats.
import requests
# Get data on only confirmed cases
api_response = requests.get('https://covid19api.herokuapp.com/confirmed')
# Print latest data for location ID 100: California, USA
print(api_response.json()['locations'][100]['latest'])
The API also has a convenient endpoint at /latest which will simply show you the global totals for active cases and deaths.
Virus Tracker API
Another option is the free API available from thevirustracker.com. I’m somewhat hesitant to recommend this service as it has all the hallmarks of somebody looking to capitalize on a disaster and the site seems to go down regularly. That said, it’s the best documented of any of the APIs I’ve seen so far.
![]()
This API also gives you a number of very convenient data points that don’t seem to be available from other sources. For example it allows you to see how many of the cases are considered serious, as well as how many new cases have been added today. The API also includes a listing of recent news items related to the country you have selected, which could be useful if you’re looking to make your own dashboard.
import requests
# Request fails unless we provide a user-agent
api_response = requests.get('https://thevirustracker.com/free-api?countryTotal=US', headers={"User-Agent": "Chrome"})
covid_stats = api_response.json()['countrydata']
# Break out individual stats
print("Total Cases:", covid_stats[0]["total_cases"])
print("New Today:", covid_stats[0]["total_new_cases_today"])
Knowledge is Power
After playing around with these data sources for a bit, you’re likely to notice that they don’t always agree. Things are moving so quickly that even when going straight to the source like this, there’s a certain margin of error. A reasonable approach may be to take multiple data sources and average them together, though that assumes you’re able to drill down to the same level on each service.
As stated in the intro of this article, what you do with this information is entirely up to you. For my own purposes I put together a little network attached display so I can monitor the total number of cases in the United States, and honestly it’s been a sobering experience. Seeing the number increase by thousands each day has really put the situation into focus for me; and I know that by the time this article is published, the number shown in the picture will be considerably lower than the latest figures.
I can’t say I’m particularly glad to have the latest numbers on my desk every morning, but I’d rather know what we’re up against than remain oblivious. Something tells me many of you will feel the same way. If you’re looking for less of a downer, you could always roll in some happier data, perhaps even showing an animation whenever the number of recoveries goes up. Stay safe out there.
No comments:
Post a Comment